








데이터 과학, 기계 학습 및 인공 지능
시장은 붐에 있습니다.
데이터 과학은 과학적 방법, 프로세스 및 알고리즘을 사용하여 통찰력, 이해 및 지식을 기본적으로 구조화 또는 구조화되지 않은 데이터를 기본적으로 변환합니다.
r 및 python
는 데이터 과학의 통계, 수학, 데이터 랭킹, 탐사 및 시각화에 사용되는 무료 오픈 소스 프로그래밍 언어입니다. 그것은 구조화 된 (조직 된) 및 반 구조화 된 (반 조직 된) 데이터를 처리 할 수 있습니다.
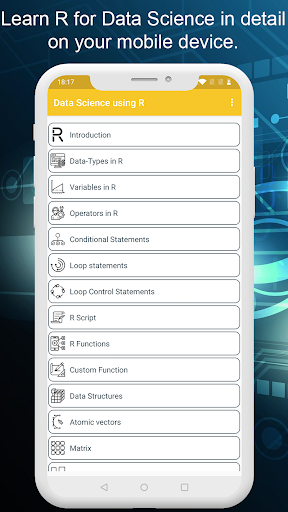
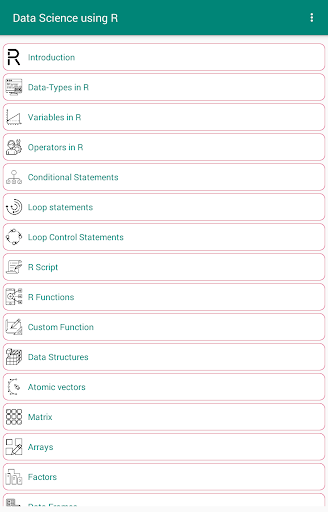
데이터 과학을 위해 R을 배우려면 우리는 다음과 같이 모든 측면을 다루었습니다.
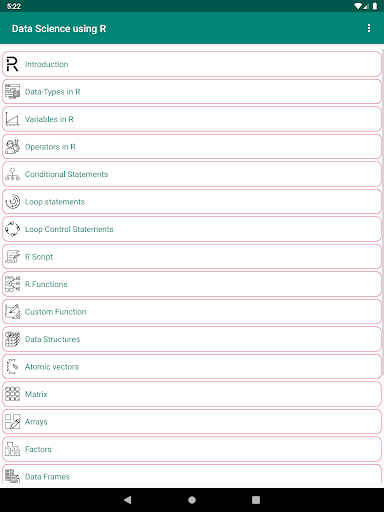
소개 • 소개
r
루프 제어 문 • R 스크립트
• r 기능
• 사용자 정의 기능
• 데이터 구조
⁎ 원자 벡터
⁎ 매트릭스
⁎ 배열
⁎ 요소
⁎ 데이터 프레임
⁎ 목록
데이터 내보내기 - 데이터 구조에 값 할당
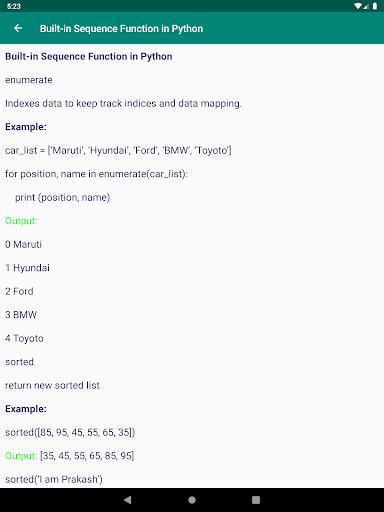
• 데이터 조작 / 변환 • 기본 R의 기능 적용 • DPLER 패키지
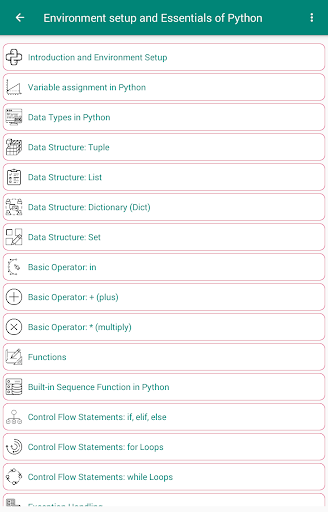
✤ 환경 설정 및 Python의 필수
✽Introduction 및 환경 설정
파이썬의 할당 → 파이썬의 할당 → 디지털 파이썬 → 데이터 구조 : 튜플
✽data 구조 : 목록
data 구조 : 사전 (Dict)
✽data 구조 : 설정 비스틱 운영자 :
✽ ✽ 운영자 : (더하기)
✽basic Operato R : * (곱하기)
Python의 시퀀스 → Control Flow Statements : Eff, Elif, Else
파이썬에서 숫자가있는 마법 계산 ▌ 배열의 타이프 ■ NDARRAY의 ✽ 트리 벨트 요소
œCopy 및 뷰
✽universal 기능 (UFunun)
✽ Shape 조작
✽ 브로드 캐스팅
✽inear 대수학
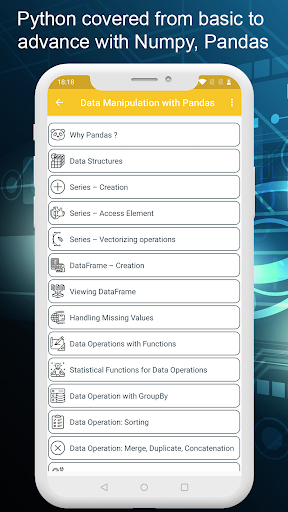
✤ 댄스가있는 │Data
• 왜 팬더?
• 시리즈 - 생성
• 시리즈 - 생성
• 시리즈 - 액세스 요소
• 시리즈 - vector
• 데이터 프레임 - 생성
• 데이터 프레임보기
값
• 기능이있는 데이터 작업
• 데이터 작업을위한 통계 기능 • GroupBy가있는 데이터 작업
• 데이터 작동 : 정렬
• 데이터 작동 : 병합, 중복, 연결
• SQL O. 팬지스의
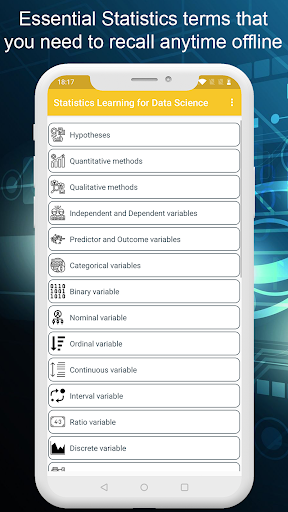
통계
이 분야에서 학습을 시작하는 데 중요한 부분입니다. 통계에 사용 된 용어는 매우 이상하고 초보자를 위해 이해하기가 어렵습니다. 그래서 우리는 최선을 다했습니다. 초보자, 중급 또는 데이터 과학, 기계 학습, AI 분야에서 초보자, 중급 또는 고급 수준의 사람들을 위해이 용어를 설명하기 위해 여기서 우리는 여기에 통계에 사용 된 많은 용어를 다루고 있습니다 -
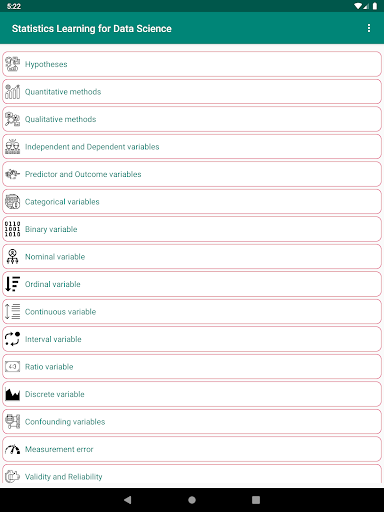
• 정량 메소드
• 정성 방법 • 독립적이고 종속적 인 변수 • 예측기 및 결과 변수
• 분류 변수
• 바이너리 변수
• 공칭 변수
• 서수 변수
• 연속 변수
• 비율 변수
• 비율 변수
• 개별 변수
• 개별 변수
• 혼란스러운 변수
• 측정 오류
• 유효성 및 신뢰성
• 두 가지 데이터 수집 방법
• 변동의 종류
• 체계적인 변화 • 체계적인 변화
• 주파수 배포
• 평균
• 중앙값 • 모드
• Disce 데이터로
• 범위로
• 사 분위 범위로
• 분위수로
• 확률의 분포 rsion • 표준 편차로
로
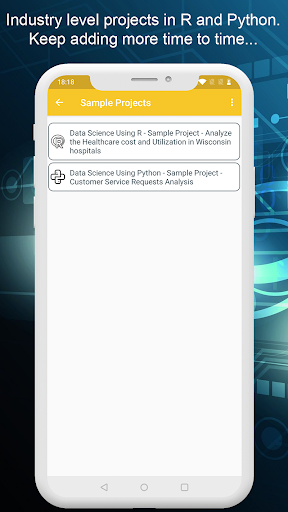
이 응용 프로그램의 그림에서 가장 중요한 장점이 샘플 프로젝트를 제외하고 전체 자료 오프라인으로 사용할 수 있으며 샘플 프로젝트 부분은 IT 웹 기반 정기적으로 계속 추가하기 때문에 온라인 상태입니다.
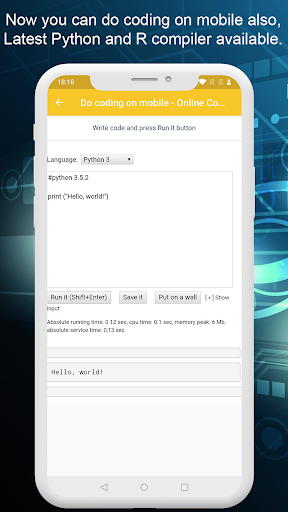
모바일 장치의 온라인 컴파일러, 모바일에 코드를 작성하고 출력을 보려면 실행할 수 있습니다.
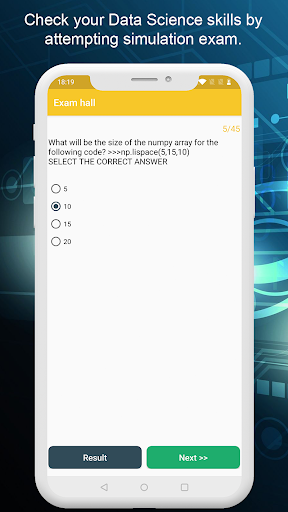
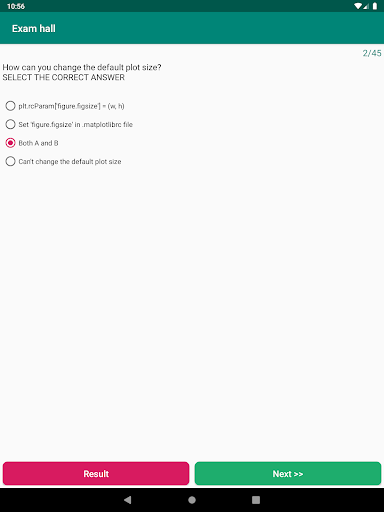
시뮬레이션 테스트 / 시험 -이 시뮬레이션 시험을 시도하면 데이터 과학에서 지식을 확인하십시오. 각 질문에는 4 가지 옵션과 1 개의 정답이 있습니다.
Now you can make app Ad Free too.
9Apps 4.9