

Speech to Text AI / เครื่อง / การถอดความของมนุษย์
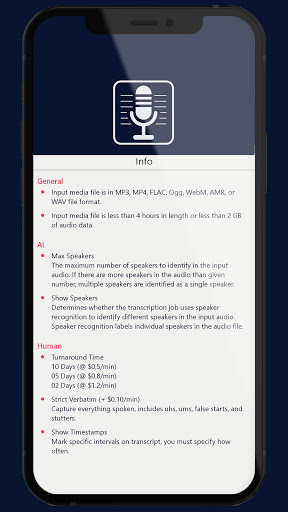
👉 Ai
✔ Max Speakers
O จำนวนสูงสุดของลำโพงเพื่อระบุในเสียงอินพุตหากมีลำโพงมากขึ้นในเสียงมากกว่าจำนวนที่กำหนดลำโพงหลายตัวจะถูกระบุว่าเป็นลำโพงเดียว
✔แสดงลำโพง - O กำหนดว่างานถอดความใช้การจดจำลำโพงเพื่อระบุลำโพงที่แตกต่างกันในเสียงอินพุตฉลากการจดจำลำโพงลำโพงแต่ละตัวในไฟล์เสียง
👉มนุษย์
✔เวลาตอบสนอง
O 10 วัน ($ 0.5 / นาที) - O 5 วัน ($ 0.8 / นาที)
O2 วัน ($ 1.2 / นาที)
✔ข่มขู่อย่างเข้มงวด ($ 0.10 / นาที)
o จับภาพทุกอย่างที่พูดรวมถึง UHS, UMS, การเริ่มต้นที่ผิดพลาดและ stutters
✔แสดงการประทับเวลา
o เครื่องหมายเฉพาะในการถอดความ - O คุณต้องระบุความถี่บ่อยแค่ไหน
Updated
Bug Fixes

![Audio To Text Converter [FREE] How to Transcribe Audio to Text screenshot 2](https://i.ytimg.com/vi/8yHwRZl4Lrs/mqdefault.jpg)



9Apps 4.9
















